Statistical Natural Language Tagging

Description:
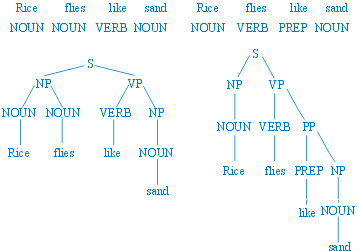
Statistical Natural Language Tagging [CHARNIAK93] consists of assigning a lexical category to each word in a text. Usually, the first step in the parsing process is to identify which lexical category (noun, verb, etc) each word in the sentence belongs to, i.e to tag the sentence. The difficulty of the tagging process comes from the lexical ambiguity of the words: many words can be in more that one lexical class. The assignment of a tag to a word depends on the assignments to the other words. Let us considered the following words and their tags.
| Rice: | NOUN |
| flies: | NOUN, VERB |
| like: | PREP, VERB |
| sand: | NOUN |
The most common statistical models for tagging are
based on assigning a probability to a given tag according to its neighboring
tags (context). Then the tagger tries to maximize the total probability
of the tagging of each sentence. The raw data to obtain this probability
are extracted from the training text. That is, we need a hand-tagged
text such as the one provided in [BROWN79]. Then,
the probability of a sentence can be define as the sum of the probabilities
of the context of each word 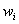 :
(
:
(
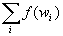 ).
The probability of a context can be defined as
).
The probability of a context can be defined as
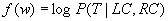
where P(T|LC, RC) is the probability that the tag of word w is T, given that its context is formed by the sequence of tags LC to the left and the sequence RC to the right. This probability is estimated from the training text as
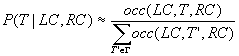
where occ(LC, T, RC) is the number of occurrences of the
list of tags LC, T, RC in the training table and 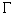 is the set of all possible tags of .
is the set of all possible tags of .
Click here to get this description in tex format and here to get the figure in eps format.
Instances and best known solutions for those instances:
The best statistical models typically perform at about a level of correctness oof the 96% [BRILL95,ARAUJO02].
Related Papers:
- [ARAUJO02] L. Araujo. "Part-of-speech tagging with evolutionary algorithms." In Proc. of the Int. Conf. on Intelligent Text Processing and Computational Linguistics (CICLing-2002), Lecture Notes in Computer Science 2276, p. 230-239. Springer-Verlag, 2002.
- [BRILL95] E. Brill. Transformation-based error-driven learning and natural language processing: A case study in part of speech tagging. Computational Linguistics, 21(4), 1995.
- [BROWN79] W.N. Francis and H. Kucera. "Brown Corpus of Standard American English". Brown University, Providence, RI, possible access online at the Linguistic Data Consortium LDC site.
Click here to get the bibliography in bibtex fotmat.
![]() Last Updated:
4/2/03
For any question or suggestion, click here
to contact with us.
Last Updated:
4/2/03
For any question or suggestion, click here
to contact with us.