|
|
|
|
|
|
|
|
The Neural Networks
Training Problem
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
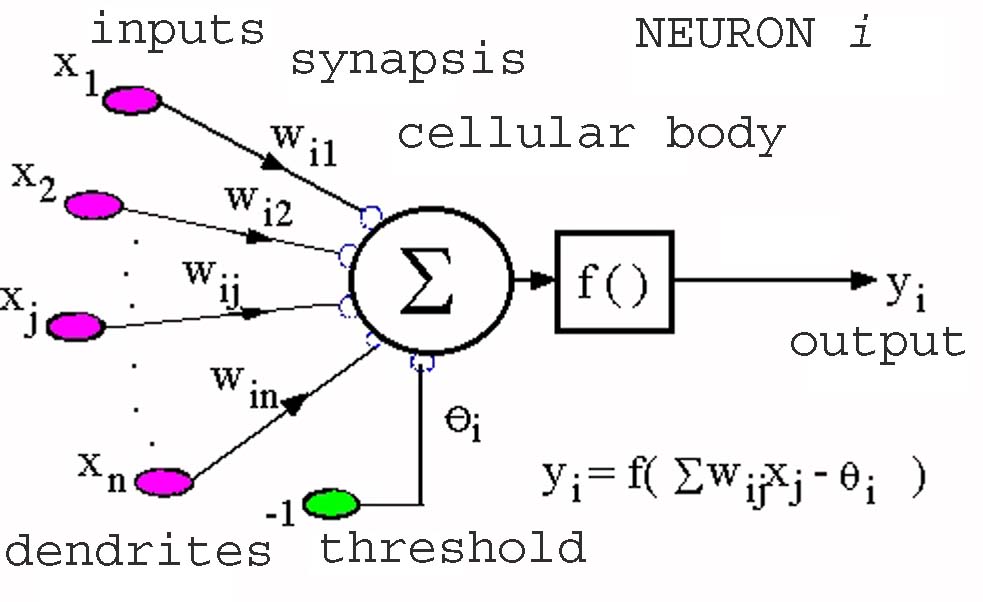
A neural network (NN in the following) is formed by a set of process units or
neurons interconnected. The topology of the NN can be specified by a directed
graph where vertices are neurons and arcs are interconnections. Each
interconnection has a real value associated with it called its synaptic
weight. We can distinguish three types of neurons: input neurons, output
neurons and hidden neurons. The outputs of the input neurons are established
externally by the environment and constitute the input of the NN. The output
of any non-input neuron is computed by applying an activation function to the
weighted sum of its inputs. These inputs are computed after the outputs of
every incoming neuron weighted by its associtaed
synaptic weight. The outputs of the output neurons constitute de final output
of the NN. When we present an input vector to the network an output vector is
obtained by propagation of the values through the hidden neurons towards the
output layer of neurons.
The pair input vector/desired output vector is called a pattern.
Training a NN consists in adjusting the synaptic weights in such a way that
the NN learn a set of patterns (i.e., it works out the desired output for
every input vector). This problem can be specified as an optimization
problem. The goal is to minimize the error between the actual output of the
NN and the desired output, computed for all the input vectors. This error can
be calculated by means of the Root Medium Square Error (RMSE) whose
expression is:
|
|
||
|
|
|
|
|
|
|
|
Problem Instances:
Neural networks can be applied to pattern classification and function
approximation. Widely used instances of the pattern classification problem can
be obtained from the UCI Machine Learning Repository. However, Prechelt in [PRE94] proposed a benchmark set of instances and
benchmarking rules in order to get a standard analysis of results, and thus
allow researches to meaningfully compare their results. This benchmark
(available for anonymous FTP in ftp://ftp.ira.uka.de/pub/neuron/proben1.tar.gz)
includes the following instances:
For the function
approximation problem we present here the definition of 15 functions previously
used in the literature [FML06]
|
|
||
|
|
|
|
|
|
|
|
Related Papers:
[PRE94] Lutz Prechelt. PROBEN1 - A Set of Neural Network Benchmark Problems and Benchmarking Rules. Technical Report 21, Fakultät für Informatik Universität Karlsruhe, 76128 Karlsruhe, Germany, September 1994. [SD00] Randall S. Sexton and Robert E.
Dorsey. Reliable Classification Using Neural Networks: a Genetic Algorithm
and Backpropagation Comparison. Decision Support
Systems, 30:11-22, 2000. [CASL01] C. Cotta, E. Alba, R. Sagarna and P. Larrañaga.
Adjusting Weights in Artificial Neural Networks using Evolutionary
Algorithms. Estimation of Distribution Algorithms. A New Tool for
Evolutionary Computation. Chapter 18, pages 357-373. Kluwer
Academic Publishers, P. Larrañaga and J.A. Lozano
(eds.), 2001. [FML06] El-Fallahi A., Martí, R., and Lasdon, L.
(2006), Path Relinking and GRG for Artificial
Neural Networks, European Journal of Operational Research, 169, pp. 508-519. |
|
||
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|